> For the complete documentation index, see [llms.txt](https://www.damonyuan.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://www.damonyuan.com/readme.md).
# Damon's Blog
> The magic you are looking for is in the work you're avoiding.
## Gems
### 2026
#### August
* 1: [Runtime Polymorphism Without Objects or Virtual Functions](https://www.fluentcpp.com/2020/05/15/runtime-polymorphism-without-virtual-functions/)
> * Runtime Polymorphism on Class vs Runtime Polymorphism on Object
> * To return a polymorphic object, a function has to use a (smart) pointer; Indeed, if it were to return Base by value, the object would be sliced: only the Base part would be returned, and not the Derived part.
> * [Inheritance Without Pointers](https://www.fluentcpp.com/2021/01/29/inheritance-without-pointers/): a technique to use inheritance and virtual functions without having to use pointers.
> * [Polymorphic clones in modern C++](https://www.fluentcpp.com/2017/09/08/make-polymorphic-copy-modern-cpp/)
> * [How std::any Works](https://www.fluentcpp.com/2021/02/05/how-stdany-works/)
#### July
* 10: [Rust Interior mutability](https://doc.rust-lang.org/reference/interior-mutability.html)
> When to use it? (it can also be applied to C++ mutable members when needed)
>
> * Mock Objects: When implementing a trait that defines immutable methods, but your test mock needs to log or track internal calls.
> * Logical Immutability: When an object is conceptually immutable to the outside world, but needs to update internal caches, counters, or metrics during **read** operations.
> * Cyclic Data Structures: When building complex graphs or nodes where multiple parents might need shared, mutable access to a child node.
* 9: C++ ownership
>
* 8: [什么是 ReAct?一个例子看懂 AI Agent 原理](https://mp.weixin.qq.com/s/xScGO9bmL8H3IOjEUDTnuA)
* 7: [Aeron: Client Concurrency Model](https://github.com/aeron-io/aeron/wiki/Client-Concurrency-Model)
* 6: [Stop Naming Your Variables "Flag": The Art of Boolean Prefixes](https://thatamazingprogrammer.com/posts/stop-naming-your-variables-flag-the-art-of-boolean-prefixes/)
* 5: [ASCII control characters in my terminal](https://jvns.ca/blog/2024/10/31/ascii-control-characters/)
* 4: [Rust vs C++: Competition or Evolution in Systems Programming for 2026](https://blog.jetbrains.com/rust/2025/12/16/rust-vs-cpp-comparison-for-2026/)
* 3: [C++ Executors: the Good, the Bad, and Some Examples](https://accu.org/journals/overload/29/164/teodorescu/)
* 2: [Adverse Selection & Markouts](https://machow.ski/posts/markouts_and_adverse_selection/#measuring-adverse-selection)
> * [Information Effects on the Bid-Ask Spread](https://onlinelibrary.wiley.com/doi/full/10.1111/j.1540-6261.1983.tb03834.x): a paper that models a market maker’s quotes as writing free put and call options, highlighting the risk that the Market Maker (MM) exposes themselves to by simply quoting.
> * [The Role of Binance in Bitcoin Volatility Transmission](https://ideas.repec.org/p/arx/papers/2107.00298.html): “The tether-margined perpetual contract on Binance is clearly the main source of volatility, continuously transmitting strong flows to all other instruments and receiving very little volatility from other sources.”
* 1: [Pitchfork](https://github.com/vector-of-bool/pitchfork)
> Pitchfork is a set of conventions for native C and C++ projects. For example, the layout. [base64pp](https://github.com/matheusgomes28/base64pp): an example with conan
>
> * [Introduction to Conan 2 - The Best C++ Package Manager?](https://www.youtube.com/watch?v=U-_RbUqDSTc\&t=390s)
#### June
* 19: [Debug Adapter Protocol](https://microsoft.github.io/debug-adapter-protocol/)
* 18: [Get started with Bazel quickly](https://bazel.build/start/cpp)
* [Choosing a Build System for C++: CMake, Bazel, Meson, and Beyond (2026)](https://gist.github.com/MangaD/26ef92a1e1efd967c3e0188dc0591e83)
* 17: [C++ 'Type Erasure' Explained](https://davekilian.com/cpp-type-erasure.html)
* 16: [Pointer Aliasing](https://docs.amd.com/r/en-US/ug1079-ai-engine-kernel-coding/Pointer-Aliasing)
> * Pointer aliasing occurs when different pointer names access the same memory location. The strict aliasing rule in C/C++ means that pointers are assumed not to alias if they point to fundamentally different types. Aliasing introduces strong constraints on program execution order.
> * The strict aliasing rule dictates that pointers are assumed not to alias if they point to fundamentally different types. char\* and void\* are exceptions. These can alias to any other data type. This is shown in the following graphic which shows the object universes and the associated pointers.
* 15: [Using std::expected from C++23](https://www.cppstories.com/2024/expected-cpp23/)
> aka., rust `Result`
* 14: [Stack Overflow: Understanding std::inout\_ptr and std::out\_ptr in C++23](https://stackoverflow.com/questions/68918312/understanding-stdinout-ptr-and-stdout-ptr-in-c23)
* 13: [The Flyweight Design Pattern: Efficient Resource Management for Large Systems](https://medium.com/@kalanamalshan98/the-flyweight-design-pattern-efficient-resource-management-for-large-systems-37f618efbb43)
> * [Game Programming Patterns - Flyweight](https://gameprogrammingpatterns.com/flyweight.html)
> * [GeeksforGeeks: Flyweight Design Pattern](https://www.geeksforgeeks.org/system-design/flyweight-design-pattern/)
* 12: [Mechanical Sympathy: Simple Binary Encoding](https://mechanical-sympathy.blogspot.com/2014/05/simple-binary-encoding.html)
> Regarding the general performance of the stubs, we have observed that c++ has a very marginal advantage over the Java which we believe is due to runtime inserted Safepoint checks.
>
> * [sbepp is a zero-overhead C++ implementation of Simple Binary Encoding (SBE).](https://github.com/OleksandrKvl/sbepp)
> * [Java OTF User Guide](https://github.com/aeron-io/simple-binary-encoding/wiki/Java-OTF-User-Guide)
> * [SBE Cpp User Guide](https://github.com/aeron-io/simple-binary-encoding/wiki/Cpp-User-Guide)
> * [SBE Design Principles](https://github.com/aeron-io/simple-binary-encoding/wiki/Design-Principles)
* 11: [Matrix-Calculus-Tutorial](https://github.com/LynnHo/Matrix-Calculus-Tutorial)
> TODO
* 10: [Calculus on Computational Graphs: Backpropagation](https://colah.github.io/posts/2015-08-Backprop/)
> Backpropagation
* 9: [matrix-calculus - Understanding numerator/denominator layouts](https://stats.stackexchange.com/questions/553883/matrix-calculus-understanding-numerator-denominator-layouts)
> Thumb Rule:
>
> * Numerator Layout has dimensions equivalent to numerator and transpose of the denominator
> * Denominator Layout has dimensions equivalent to denominator and transpose of the numerator
> * [Understanding numerator/denominator layout in matrix-calculus](https://math.stackexchange.com/questions/4317715/understanding-numerator-denominator-layout-in-matrix-calculus)
> * [Matrix Calculus for Machine Learning](https://medium.com/analytics-vidhya/matrix-calculus-for-machine-learning-e0262f0eaa8e)
> * [Vector and matrix derivatives](https://www.kamperh.com/data414/notes/03b_vector_matrix_derivatives_notes.pdf): TODO
* 8: [Overview of PyTorch Autograd Engine](https://pytorch.org/blog/overview-of-pytorch-autograd-engine/)
> Understanding autograd
>
> * [Forward Automatic Differentiation](https://liqimai.github.io/blog/Forward-Automatic-Differentiation/)
> * [Chain Rule Derivative in Machine Learning](https://www.geeksforgeeks.org/data-science/chain-rule-derivative-in-machine-learning/)
> * book: [MATHEMATICS FOR MACHINE LEARNING](https://mml-book.github.io/book/mml-book.pdf)
> *
* 7: [OrderAdderMain.java in Chronicle-Queue-Demo](https://github.com/OpenHFT/Chronicle-Queue-Demo/blob/main/order-processor/src/main/java/town/lost/oms/OrderAdderMain.java)
* 6: [Build an MCP server](https://modelcontextprotocol.io/docs/develop/build-server)
> TODO
* 5: [结算业务模型](https://mp.weixin.qq.com/s/u4pfGrDcPs-39IakPpOR8A)
* 4: [代码定义结构,权重存储知识:一个例子看懂大模型如何推理](https://mp.weixin.qq.com/s/TM9lv6b-9AH8O9ZiApgTBA)
> 下载一个开源模型时,经常会看到一种奇怪现象:模型代码只有几十 KB,权重文件却有几个 GB,甚至几十 GB。
* 3: [State Machine Replication, and Why You Should Care](https://signalsandthreads.com/state-machine-replication-and-why-you-should-care/)
> TODO
* 2: [从 Trade 与 OrderBook 分解订单流](https://mp.weixin.qq.com/s/x1HspU7D75Y2HdhNRkV8Xw)
> * Trade Imbalance = M\_buy − M\_sell
> * OFI = ΔBidDepth − ΔAskDepth
> * Full Order Flow = M\_buy − M\_sell + L\_buy − L\_sell − C\_buy + C\_sell
> * [四家交易所 Order Book 推送与 OFI 统一处理](https://mp.weixin.qq.com/s/IovB-xnbAtzSTfWaZAgswQ)
> * [订单流不平衡之 Taker Imbalance](https://mp.weixin.qq.com/s/Dfq0kDN9Iu8WJsKjb-1bwQ)
> * [高频因子:从 Trade、OrderBook 到预测目标](https://mp.weixin.qq.com/s/XXSJ1vninayzeu6nLldpnw)
* 1: [做早餐 与 低延迟 设计之道](https://mp.weixin.qq.com/s/1tItCx5CacCU03H8rE-8rw)
> 尽可能把计算与访存前置,以空间换时间。
#### May
* 20: [Proof Engineering: The Message Bus](https://medium.com/prooftrading/proof-engineering-the-message-bus-a7cc84e1104b)
> sequencer architecture
* 19: [Memory Consistency Models: A Tutorial](https://jamesbornholt.com/blog/memory-models/)
> * Sequential Consistency: The most intuitive model, where the results of execution are as if all operations were executed in some sequential order, and the operations of each individual thread appear in this sequence in the order specified by its program.
> * Total Store Order (TSO): A weaker model than sequential consistency, where writes from a single thread are seen by other threads in the order they were issued, but reads may be reordered with respect to writes. This allows for certain optimizations while still providing a reasonable level of consistency.
> * Partial Store Order (PSO): An even weaker model than TSO, where writes from a single thread may be seen by other threads in any order. This allows for more aggressive optimizations but can lead to more surprising behaviors.
> * Relaxed Memory Order: The weakest model, where there are no guarantees about the order of memory operations. This allows for maximum optimization but can lead to very counterintuitive behaviors if not used carefully.)
* 18: [Introduction of Intel Thread Building Blocks (Intel TBB)](https://wsthub.medium.com/introduction-of-intel-thread-building-blocks-intel-tbb-88f47bb3749d)
> TBB takes ‘for’ loop or ‘while’ loop, and breaks them down into small chunks of task, distributing them automatically on available cores. It decides which cores to use, and if a core is more busy than other ones, it shifts the tasks allocated for the busy core to another.
* 17: [Trying out C++26 executors](https://mropert.github.io/2025/11/21/trying_out_stdexec/)
> * [Parallelizing C++ using Execution Policies](https://azeemba.com/posts/cpp17-execution-policy.html?utm_source=perplexity)
* 16: [Mathematical Foundations of Reinforcement Learning](https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning)
> 强化学习数学基础
* 15: [Jane Street讲座:互斥锁慢么?](https://mp.weixin.qq.com/s/q6bgtYlz61QZTgiUfFfHSQ)
> * 如果我们想在纯读场景下获得 线性扩展 的性能,唯一解是:读者(Readers)绝对不能写入任何共享状态!连读写锁里的读者计数器也不能写!这意味着读操作必须是无等待的(Wait-free)且绝不触发缓存行 Invalid。
> * Left-Right 数据结构: 通过牺牲写者的延迟(并且引入 2 倍内存开销),换取了读者纯粹的、无硬件竞争的并行访问。测试显示,Left-Right 数据结构的读吞吐量随着核心数增加呈现完美的线性正比例增长,轻松突破数十亿次/秒。
> * 大多无锁结构只能提供最终一致性。
> * 跨核心的“缓存一致性协调(共享写)”才是性能杀手。
> * 即使是标榜为 Lock-Free 或读写锁的代码,如果包含了频繁的共享变量 CAS / Atomic 加减操作,在极高并发下依然会遭遇严重的性能崩塌。
* 14: [python-fix-msg-parser](https://github.com/DiwashRai/python-fix-msg-parser)
> A simple Python library for parsing FIX (Financial Information eXchange) messages.
* 13: [compile-testing](https://github.com/google/compile-testing)
> A library for testing javac compilation with or without annotation processors. It allows you to write tests that assert whether a given piece of Java source code compiles successfully, fails to compile, or produces specific compiler errors or warnings. This is particularly useful for testing annotation processors, which generate code at compile time based on annotations in the source code.
* 12: [manifold](https://github.com/manifold-systems/manifold)
> Manifold is a Java compiler plugin, its features include Metaprogramming, Properties, Extension Methods, Operator Overloading, Templates, a Preprocessor, and more.
>
> * Instead of generating .java files beforehand, Manifold acts as a direct Java Compiler (javac) Plugin. It intercepts the compilation process on the fly. As the compiler parses your code, Manifold directly supplies the types or extensions into the compiler's memory. It does not require you to pre-generate source files.
> * [Quick Guide to MapStruct](https://www.baeldung.com/mapstruct)
> * MapStruct operates as a standard Java Annotation Processor (JSR-269). When you compile your project, the annotation processor reads your mapping interfaces, generates completely new .java implementation files in your target/generated-sources folder, and then hands those newly generated files over to the compiler.
> * MapStruct relies on reading annotations to write new source files before compilation finishes. Manifold sits directly inside the compiler, actively expanding Java's type system and altering how the compiler understands code while it builds your project.
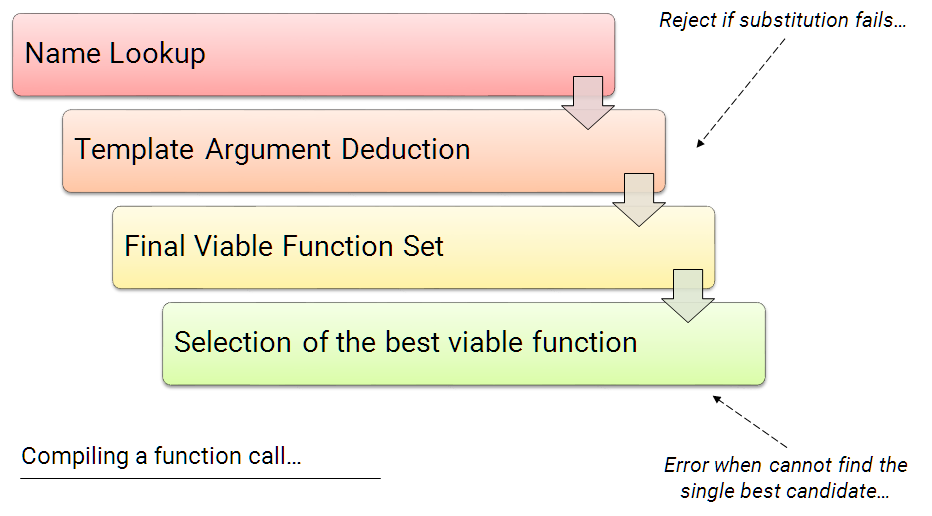
* 11: [Notes on C++ SFINAE, Modern C++ and C++20 Concepts](https://www.cppstories.com/2016/02/notes-on-c-sfinae/)
>
>
> * [How Does std::enable\_if work?](https://stackoverflow.com/questions/25284499/how-does-stdenable-if-work)
> * `template struct enable_if { typedef T type; };`: if true, using type = T as a member type.
> * `template struct enable_if {};`: if false, no type member.
> * `template::value, int>::type = 0> void foo(const T& bar) { isInt(); }`: Type Parameters vs. Non-Type Parameters
> * [std::numeric\_limits as a Condition](https://stackoverflow.com/questions/25251380/stdnumeric-limits-as-a-condition)
> * [C++ Templates: What is std::enable\_if and how to use it?](https://medium.com/@sidbhasin82/c-templates-what-is-std-enable-if-and-how-to-use-it-fd76d3abbabe)
* 10: [An introduction to C++ Traits](https://accu.org/journals/overload/9/43/frogley_442/)
> Think of a trait as a small object whose main purpose is to carry information used by another object or algorithm to determine "policy" or "implementation details". - Bjarne Stroustrup
>
> * ::value returns a constant value (typically a bool, int, or size\_t). It is used for traits that query a property of a type, such as "is this type a pointer?".
> * ::type returns a type. It is used for traits that perform a transformation on a type, such as "remove the const qualifier".
* 9: [跟“不承认大学生就业难”的郑强教授讲讲逻辑](https://mp.weixin.qq.com/s/JjQ_JyByT14KF-cfCDXXpw)
> * 形式逻辑(Formal Logic)
> * 同一律(Law of Identity)
> * 矛盾律(Law of Non-Contradiction)
> * 排中律(Law of Excluded Middle)
> * 充足理由律(Law of Sufficient Reason)
> * 辩证法(dialectics)
> * 对立统一规律(the law of unity of opposites)
* 8: [读懂AI史上最重要的一篇论文《Attention Is All You Need》](https://www.youtube.com/watch?v=_VaEjGnHgOI\&t=419s)
> * Background & Motivation
> * Limitations of Old Models (RNN/CNN)
> * Sequential processing is slow (can't be parallelized)
> * Struggles with long-range dependencies in text
> * The Core Problem: How to process an entire sentence in parallel, understanding the relationship between all words, regardless of their distance.
> * Core Concept: The Attention Mechanism
> * In a Nutshell: A method that helps the model focus on the most relevant parts of the input when producing an output
> * The Three Musketeers (Q, K, V):
> * Query (Q): What am I looking for? (e.g., "I need a fruit").
> * Key (K): What do I have to offer? (e.g., "I am an apple", "I am a car").
> * Value (V): The actual information (e.g., the taste of the apple, the color of the car).
> * How it works: The Query is matched against all Keys to find the best fit, and then the corresponding Values are retrieved.
> * Detailed Model Architecture (The Transformer)
> * Overall Structure: An Encoder and a Decoder
> * The Encoder (Understanding the Input)
> * Input
> * Step 1: Input Embedding: Converts each word into a numerical vector.
> * Step 2: Positional Encoding: Adds information about the position of each word
> * Step 3: Self-Attention: It calculates the relationship between every word in the input sentence with every other word. This is where the Q, K, V process happens for the input sentence.
> * Step 4: Feed-Forward Neural Network: Processes the output from the attention layer.
> * Add & Norm: Each sub-layer (Attention, FFN) has a residual connection and is normalized to help with training.
> * The Decoder (Generating the Output)
> * Output: The translated or generated sentence
> * Step 1: Output Embedding + Positional Encoding: Similar to the encoder, but for the words it has generated so far.
> * Step 2: Masked Self-Attention: This is a special self-attention layer that prevents the decoder from "peeking" at future words in the output sentence during training. It can only attend to previous words in the output
> * Step 3: Cross-Attention (Encoder-Decoder Attention): This layer connects the encoder and decoder. The decoder's queries are based on its current state, and the keys/values come from the encoder's output. This allows the decoder to focus on the most relevant parts of the input sentence.
> * Step 4: Feed-Forward Neural Network: Similar to the encoder's FFN.
> * Add & Norm: Also present after each sub-layer.
> * Multi-Head Attention: Instead of having just one attention mechanism, the Transformer has multiple "heads" running in parallel. Each head can learn a different type of relationship
> * Key Innovations & Advantages
> * Parallelization: Processes all words in a sentence simultaneously, making it much faster to train than RNNs.
> * Long-Range Dependencies: The direct word-to-word connections in self-attention make it easier for the model to link words that are far apart in a sentence.
> * Interpretability: Attention weights can be visualized to see which parts of the input the model is focusing on.
* 7: [Anaconda, Miniconda, conda-forge, Miniforge & Mamba Explained in 15 Minutes!](https://www.youtube.com/watch?v=-MSLJKjH8U0)
>
* 6: [Disruptor-Style Queues in C++ for Low-Latency Software](https://towardsdev.com/disruptor-style-queues-in-cpp-for-low-latency-software-835721d644dc)
> TODO
* 5: [CPU Affinity (Core Pinning) in C++: Thread Pinning, Cache Locality, and Low-Latency Optimization](https://towardsdev.com/cpp-cpu-affinity-core-pinning-ba6749faaa65)
> TODO
* 4: [Why Your Multi-Threaded C++ Isn’t Scaling: The Brutal Reality of NUMA](https://towardsdev.com/cpp-numa-performance-memory-locality-guide-430c6e6d2664)
> Non-Uniform Memory Access (NUMA)
>
> * What: more than one socket with its own RAM sticks, and CPU + L3 Cache + its local RAM = one node, to check - `numactl --hardware`
> * Why: Page lands on whatever node the writing thread is on, when a thread being migrated to another one, the page is not migrated, so it can cause performance degradation.
> * How: to fix,
> * detect
> * `numastat -p ` to watch for lopsided memory
> * `perf stat -e node-loads,node-load-misses,node-stores,node-store-misses -p sleep 10` to quantify the problem
> * level 1
> * `numactl --cpunodebind=0 --membind=0 ./my_application` to ping to a node
> * `numactl --interleave=all ./my_application` to interleave memory across nodes. `--interleave=all` tells the kernel to spread memory pages across all NUMA nodes instead of allocating mostly from one node.
> * level 2
> * mmap to allocate virtual address space but no physical page yet, Use mmap with `MAP_NORESERVE` when you need full control.
> * OpenMP version with the same idea, schedule(static) guarantees Thread 0 always gets `[0..chunk-1]`, Thread 1 always gets `[chunk..2*chunk-1]`, etc.
> * level 3
> * Explicit NUMA Allocation
> * summary:
> * Partition your data by NUMA node. Route work to the node that owns the data. This is how ScyllaDB, DPDK, and the Linux kernel actually work.
> * Stop thinking in terms of “threads and cores” alone — and start thinking in terms of distance between compute and data.
* 3: [Empty base optimization](https://en.cppreference.com/cpp/language/ebo)
> * Empty class has size ≥ 1 as a standalone object.
> * As a base class, its size may be zero (EBO).
> * `unique_ptr` stores the deleter in a way that exploits EBO, so stateless deleters cost nothing.
> * That’s why a capture‑less lambda is preferable over a function pointer for custom deleters – the lambda is an empty class and results in a smaller `unique_ptr`.
> * std::unique\_ptr\: The deleter is a function pointer. It is not a class type, so EBO does not apply. The pointer takes one word of storage, making unique\_ptr two words.
> * std::unique\_ptr\: The deleter is an empty class. EBO applies, and unique\_ptr remains one word (just the raw pointer).
> * Even a capture‑less lambda is an empty class—the closure type has no data members. So it behaves identically to a hand‑written stateless functor.
* 2: [Manifold](http://manifold.systems/)
> For java Meta-programming. Java SPI cannot modify the existing code, but Manifold can. It uses a custom classloader to load the generated code and modify the bytecode of existing classes at runtime. It also provides a powerful type system that allows you to define new types and use them in your code as if they were built-in types.
* 1: [Quick Guide to MapStruct](https://www.baeldung.com/mapstruct)
> MapStruct is a code generator that simplifies the implementation of mappings between Java bean types based on a convention-over-configuration approach. [MapStruct](https://mapstruct.org/)
#### April
* 12: [Juan Alday: Why C++ Wins in Finance](https://www.youtube.com/watch?v=InLxLEqg_fs)
> * \~ 30us: parse 2us; risk check 5us; route 3us; network 20us
> * why C++ wins in finance:
> * zero GC pause
> * memory layout control
> * kernel bypass
> * predictable codegen
> * key features
> * concepts: constrains become readable requirements, not SFINAE mess
> * ranges: declare what you want, not how to get it, and better loop unrolling
> * std::execution: composable async pipelines with typed channels
* 11: [Implementing a Finite State Machine in C++](https://www.aleksandrhovhannisyan.com/blog/implementing-a-finite-state-machine-in-cpp/)
> * [StateMachine](https://github.com/endurodave/StateMachine)
* 10: [Things you didn't know about indexes](https://jon.chrt.dev/2026/04/15/things-you-didnt-know-about-indexes.html)
> TODO
* 9: [Fix for Remote Desktop Error code 0x207 on Mac for Ubuntu](https://dev.to/emile1636/rdp-error-code-0x207-on-mac-for-ubuntu-24-d6d)
> headache...
* 8: [apfel: The free AI already on your Mac](https://apfel.franzai.com/#)
> macOS Tahoe ships with a 3B parameter LLM. apfel gives you CLI access with one brew install. No model downloads, no API keys, no configuration needed, just works. apfel: This software does not run on macOS versions older than Tahoe.
* 7: [Big-Endian Testing with QEMU](https://www.hanshq.net/big-endian-qemu.html)
> TODO
* 6: [Machine Learning: A Practitioner's Mental Model](https://github.com/dreddnafious/thereisnospoon/blob/main/ml-primer.md)
> TODO
* 5: [Claude Code Unpacked](https://ccunpacked.dev/)
> TODO
* 4: [Consistent hashing](https://eli.thegreenplace.net/2025/consistent-hashing)
> TODO
* 3: [Anatomy of the .claude/ Folder](https://blog.dailydoseofds.com/p/anatomy-of-the-claude-folder)
> How about copilot?
* 2: [从 LLM 到 Agent Skill](https://youtu.be/7qO8-kx3gW8?si=k75AlLd3Mqwld_Ac)
> * LLM
> * Token
> * Context
> * Context Window
> * Prompt
> * User Prompt
> * System Prompt
> * Tool
> * MCP
> * Agent
> * Agent Skill
* 1: [Concepts (C++)](https://en.wikipedia.org/wiki/Concepts_\(C%2B%2B\)#:~:text=This%20article%20needs%20additional%20citations,may%20be%20challenged%20and%20removed.\&text=This%20article%20relies%20excessively%20on,adding%20secondary%20or%20tertiary%20sources.\&text=Concepts%20are%20an%20extension%20to,standardised%20in%20C++20.)
> different places in a function template signature where a constraint can be used,
>
> ```
> template
> requires Concept2
> Concept3 auto myFunction(Concept4 auto param) requires Concept5;
> ```
#### March
* 12: [Modern C++ In-Depth — Is string\_view Worth It?](https://medium.com/factset/modern-c-in-depth-is-string-view-worth-it-7ae7570b7830)
> * [When to use std::string\_view](https://learnmoderncpp.com/2024/10/29/when-to-use-stdstring_view/)
> * A std::string\_view object is typically implemented as a pointer and a length, so on 64-bit machines is 16 bytes in size and is best passed by value.
> * For a std::string\_view, data() returns a const char\* pointer which is not guaranteed to end with a null byte. It is important to note that there is no c\_str() member function (unlike for std::string), although std::string\_views created from literals (with suffix sv), or whole std::strings can usually be assumed to end with a null byte
> * If the arguments can be any type(s) in addition to std::string, using std::string\_view as the parameter type may be beneficial to performance.
> * If the arguments are always std::string l-values (ie. variables of type std::string) then std::string\_view gives no performance benefit, and const std::string& should be used in preference. In addition when passing values through multiple function calls, keeping const std::string& may improve performance.
> * A std::string\_view object is typically implemented as a pointer and a length, so on 64-bit machines is 16 bytes in size and is best passed by value.
> * be aware that string\_view will not extend the lifetime of a temporary object like a normal reference to const will.
* 11: [Sustainable Java Applications With Quick Warmup](https://dzone.com/articles/sustainable-java-applications-with-quick-warmup)
> Coordinated Restore at Checkpoint (CRaC) offers a Checkpoint/Restore API mechanism solution allowing the creation of an image of a running application at an arbitrary point in time ("checkpoint") and then starting the image from the checkpoint file (snapshot). CRaC snapshots ("checkpoints") include the entire state of the HotSpot process at a specific point in time.
* 10: [FastQueue](https://github.com/andersc/fastqueue)
> TODO
>
> * [FastQueue2](https://github.com/andersc/fastqueue2)
> * [boost::lockfree::spsc\_queue](https://www.boost.org/doc/libs/latest/doc/html/doxygen/classboost_1_1lockfree_1_1spsc__queue.html)
* 9: [TriviallyCopyable](https://en.cppreference.com/w/cpp/named_req/TriviallyCopyable#:~:text=of%20these%20types-,Notes,living%20volatile%20object%20is%20accessed.)
> A trivially copyable object in C++ is an object whose underlying bytes can be safely copied using low-level memory operations like std::memcpy or std::memmove. This property is crucial for performance optimizations and binary serialization.
>
> * thread: non-copyable but movable
> * mutex: non-copyable and non-movable
> * unique\_ptr: non-copyable but movable
* 8: [modern-cpp-features](https://github.com/AnthonyCalandra/modern-cpp-features/tree/master)
> !!! A repository to collect the modern cpp features of different version.
* 7: [Every C++ Concept Explained in 12 Minutes](https://www.youtube.com/watch?v=BlDXiRaNjLU)
> * const vs constexpr & consteval
> * literals: user-defined literals, raw string literals, and string\_view literals
> * the most vexing problem of C++: if a declaration can be parsed as either a function declaration or an object declaration, it is parsed as a function declaration.
> * compile-time polymorphism: concepts, type traits, and SFINAE
> * friend
> * diamond inheritance
> * std: containers, algorithms, and iterators
* 6: [From pip to uv: A Complete Guide to the Modern Python Project Management Workflow](https://www.youtube.com/watch?v=jd1aRE5pJWc)
> It helps to understand the modern Python project management workflow, which includes using tools like pip for package management, virtual environments for isolation, and uv for building and distributing Python packages. This workflow ensures that your Python projects are well-organized, dependencies are managed effectively, and your code can be easily shared and deployed.
* 5: [Using Precompiled Headers](https://doc.qt.io/qt-6/qmake-precompiledheaders.html#:~:text=Precompiled%20headers%20\(PCH\)%20are%20a,not%20need%20to%20be%20recompiled.)
> In C++, a PCH (Precompiled Header) file is a performance feature that stores an intermediate, compiled representation of a stable body of code (typically common, infrequently changed header files like the Standard Template Library or Windows API headers) to significantly speed up subsequent compilation times. The initial compilation that creates the PCH file takes longer, but later compilations that use the PCH are much faster because the compiler doesn't need to re-read and re-process the large headers repeatedly.
>
> * [Precompiled Headers in C++](https://youtu.be/eSI4wctZUto?si=7FdpiMF2wybzvwlt)
* 4: [Understanding Static in C++](https://www.youtube.com/watch?v=g4Dn2cwSrC4)
> * controls
> * linkage:
> * non-static global variable is placed into data section or BSS section;
> * when a static global variable is declared, it has only internal linkage, which restricts the variable's visibility to the translation unit (source file) in which it is defined. This means that a static global variable cannot be accessed from other source files, preventing naming conflicts and unintended interactions between different parts of a program.
> * if non-static global variable name conflicts, another way is to declare one of them as `extern` and remove the definition.
> * lifetime: how long the variable stays in memory; static is allocated before runtime and remains throughout the entire lifetime.
* 3: [What I learned building an opinionated and minimal coding agent](https://mariozechner.at/posts/2025-11-30-pi-coding-agent/)
> * TODO
* 2: [microgpt](https://karpathy.github.io/2026/02/12/microgpt/)
> * Two hundred lines, zero dependencies.
> * TODO:
> * [GPT From Zero to Hero](https://mp.weixin.qq.com/s/-VJo2kOHPSXFYaLvjPDuyA)
> * [microgpt.py](https://gist.github.com/karpathy/8627fe009c40f57531cb18360106ce95)
> * [MicroGPT explained interactively](https://growingswe.com/blog/microgpt)
* 1: [Modern C++: The Pimpl Idiom](https://medium.com/@weidagang/modern-c-the-pimpl-idiom-53173b16a60a)
> * Reduced Header Dependencies
> * Minimal Recompilation Cascade
> * Hidden Implementation
> * ABI Stability
> * Easy Refactoring
> * Dependency Management
> * Forward Declarations: Use forward declarations in the header file to avoid including the implementation header.
> * Rule of Five: Consider implementing the Rule of Five (copy/move constructors, copy/move assignment operators) if your class needs custom copy/move semantics.
> * In C++20 and beyond, modules offer an alternative way to manage dependencies and compile times. While modules are a powerful tool, Pimpl remains relevant in scenarios where you need to maintain ABI compatibility or desire strict encapsulation boundaries.
> * [Modern C++](https://medium.com/@weidagang/modern-c-cbcd565a0716)
#### February
* 8: [Big endian and little endian](https://ntietz.com/blog/endianness/)
> * If you write it into memory on a little-endian system, though, and read bytes from the address (with the remaining ones zero, very important!), then it is the same value no matter how many bytes you read. As long as you don't truncate the value, at least; 0x0A0B read as an 8-bit int would not be equal to being read as a 16-bit ints, since an 8-bit int can't hold the entire thing.
> * most modern systems (x86/x64 Macs included) are little-endian. However, this code is doing manual big-endian serialization regardless of the host byte order.
> * The purpose here is to serialize the integer into a network/protocol byte buffer in a specific byte order (big-endian / MSB first). By explicitly shifting and masking, the code bypasses the host's native endianness entirely — the result in buf is always the same regardless of whether the machine is little-endian or big-endian. If you instead did memcpy(\&buf\[2], \&timeMicros, 4) on a little-endian machine, you'd get the bytes in reversed order (0xDD, 0xCC, 0xBB, 0xAA), which would be wrong for this protocol format.
> * By using bitwise operations, you extract each byte based on the numeric value, not based on how the value is stored in memory. Bit shifts and masks operate on the integer value itself, which is independent of endianness.
> * [Why is data sent across the network converted to network byte order?](https://stackoverflow.com/questions/15859649/why-is-data-sent-across-the-network-converted-to-network-byte-order)
* 7: [Java NIO: Using Memory-mapped file to load big data into applications](https://medium.com/@trunghuynh/java-nio-using-memory-mapped-file-to-load-big-data-into-applications-5058b395cc9d)
> * [Memory-mapped files](https://learn.microsoft.com/en-us/dotnet/standard/io/memory-mapped-files)
> * [NIO Buffer](https://jenkov.com/tutorials/java-nio/buffers.html)
* 6: [Histograms and summaries](https://prometheus.io/docs/practices/histograms/)
> * The essential difference between summaries and histograms is that summaries calculate streaming φ-quantiles on the client side and expose them directly, while histograms expose bucketed observation counts and the calculation of quantiles from the buckets of a histogram happens on the server side using the histogram\_quantile() function.
> * However, aggregating the precomputed quantiles from a summary rarely makes sense. In this particular case, averaging the quantiles yields statistically nonsensical values.
> * The histogram implementation guarantees that the true 95th percentile is somewhere between 200ms and 300ms. To return a single value (rather than an interval), it applies linear interpolation, which yields 295ms in this case.
> * A summary would have had no problem calculating the correct percentile value in both cases, at least if it uses an appropriate algorithm on the client side (like the one used by the Go client ). Unfortunately, you cannot use a summary if you need to aggregate the observations from a number of instances.
> * Also, the closer the actual value of the quantile is to our SLO (or in other words, the value we are actually most interested in), the more accurate the calculated value becomes.
> * Two rules of thumb:
> * If you need to aggregate, choose histograms.
> * Otherwise, choose a histogram if you have an idea of the range and distribution of values that will be observed. Choose a summary if you need an accurate quantile, no matter what the range and distribution of the values is.
* 5: [UNDERSTANDING NEURAL NETWORKS, VISUALLY](https://visualrambling.space/neural-network/)
* 4: [Derivation and Intuition behind Poisson distribution](https://antaripasaha.notion.site/Derivation-and-Intuition-behind-Poisson-distribution-1255314a56398062bf9dd9049fb1c396)
> A classic way to approach this is by considering the probability of observing a certain number of rare events occurring in a fixed interval of time or space, with these events occurring independently and at a constant average rate.
* 3: [You don't need Kafka: Building a message queue with only two UNIX signals](https://leandronsp.com/articles/you-dont-need-kafka-building-a-message-queue-with-only-two-unix-signals)
> forms of IPC in UNIX include:
>
> * anonymous pipes
> * named pipes (mkfifo)
> * sockets
> * regular files
> * signal
>
> There are many signals we can send to a process, including:
>
> * SIGTERM - sends a notification to the process to terminate. It can be “trapped,” which means the process can do some cleanup work before termination, like releasing OS resources and closing file descriptors
> * SIGKILL - sends a termination signal that cannot be trapped or ignored, forcing immediate termination
> * SIGINT - the interrupt signal, typically sent when you press Ctrl+C in the terminal. It can be trapped, allowing the process to perform cleanup before exiting gracefully
> * SIGHUP - the hangup signal, originally sent when a terminal connection was lost. Modern applications often use it to reload configuration files without restarting the process
> * SIGQUIT - similar to SIGINT but also generates a core dump for debugging
> * SIGSTOP - pauses (suspends) a process. Cannot be trapped or ignored
> * SIGCONT - resumes a process that was paused by SIGSTOP
> * SIGCHLD - sent to a parent process when a child process terminates or stops
> * SIGUSR1 and SIGUSR2 - user-defined signals that applications can use for custom purposes
* 2: [Linux中的CFS调度器是如何一步步发明出来的](https://mp.weixin.qq.com/s/1CJE1XWn6YW94Q47xWhHBA?from=singlemessage\&isappinstalled=0\&scene=1\&clicktime=1770811877\&enterid=1770811877)
> 1. looping through the tasks
> 2. looping through the tasks with priority
> 3. looping through the tasks with quota and heuristic priority
> 4. CFS: Completely Fair Scheduler
> * check the task with the smallest virtual runtime, and run it for a small time slice, then update its virtual runtime and put it back to the red-black tree.
> * use the nic value to adjust the virtual runtime of a task, thus adjusting its priority.
> * IO bounding tasks will have smaller virtual runtime, thus higher priority, and CPU bound tasks will have larger virtual runtime, thus lower priority.
* 1: [Claude Code in Action](https://anthropic.skilljar.com/claude-code-in-action)
> TODO
>
> * Another one: [Learn Claude Code by doing, not reading.](https://claude.nagdy.me/)
#### January
* 25: Get the classpath through mvn: `mvn dependency:build-classpath -Dmdep.outputFile=cp.txt`
* 24: [Java Performance Troubleshooting with JFR: A Complete Guide — Part 2 — Diagnose Slow Java Application Response Time Using JFR](https://imedhyaweerasinghe.medium.com/java-performance-troubleshooting-with-jfr-a-complete-guide-part-2-diagnose-slow-java-0c78f72f0ba0)
* 23: [Java Service Provider Interface](https://www.baeldung.com/java-spi)
> * Java SPI -> api + impl with meta-info + app
> * Annotation processing is one usage of Java SPI. API is the Processor interface, impl is the annotation processor implementation, meta-info is the file in META-INF/services/ that lists the implementation class, app is the Java compiler that will load the annotation processor and execute it during compilation.
> * Java Instrumentation: can be used to transform existing bytecode / add extra-opens/exports to existing modules
> * [Guide to Java Instrumentation](https://www.baeldung.com/java-instrumentation)
> * [Introduction to Javassist](https://www.baeldung.com/javassist)
> * Annotation processor can only be used to generate new files, not to change existing ones.
> * [ava Annotation Processing and Creating a Builder](https://www.baeldung.com/java-annotation-processing-builder)
> * The notable exception is the Lombok library which use annotation processing as bootstrapping mechanism to include itself into the compilation process and modify the AST via some internal compiler APIs.
> * [Google AutoService](https://www.baeldung.com/google-autoservice): used for SPI, Processor is the interface, and AnnotationProcessor is the implementation that need to be found during compile time by ServiceLoader.
* 22: [An insight into the mathematical mind: Box-Muller transforms](https://www.flyingcoloursmaths.co.uk/an-insight-into-the-mathematical-mind-box-muller-transforms/)
* 21: [为什么C语言高手偏爱void\* ?](https://mp.weixin.qq.com/s/nJo7MGNT80ftVF3i2U4udQ)
> 1. generic programming
> 2. memory allocation
> 3. interface design
* 20: [链接器是如何一步步发明出来的?](https://mp.weixin.qq.com/s/Ie99bZu3fAkS2ndVOflOAA)
> 1. 编译器处理各个模块,但不必关心跨模块引用
>
> 2. 根据各个模块提供的信息来确定符号最终的内存地址并合并所有的模块为一个最终可执行文件
>
> 3. Relocation Table
>
> 4. Symbol Table
>
> * [为什么链接器能“预言”程序运行时地址?](https://mp.weixin.qq.com/s/IEf7hiY9IXSAbXytvF6Zrg)
> * 0x400000
* 19: [mmap是如何巧妙绕过传统IO性能陷阱的?](https://mp.weixin.qq.com/s/SylwBMYxNPhbvqPOSxaPWg)
> 1. zero copy
> 2. 当程序访问映射区域时,如果所需的页面不在内存中,虚拟内存子系统会自动触发缺页中断,并将相应的页面从磁盘加载到内存中。
> 3. 频繁修改分散的小数据块(如散列写入)可能导致大量缺页中断和TLB(Translation Lookaside Buffer)未命中,性能可能低于传统read/write。mmap适合需要零拷贝访问、大文件随机读或共享内存的高性能场景(如内存数据库、图像处理)。
> 4. 如果是实时系统的话,那么这种场景对操作延迟有严格上限,mmap的缺页中断和磁盘I/O延迟不可预测。
> * Chronicle Queue mitigates mmap page‑fault unpredictability with design choices aimed at determinism:
> * Preallocation and pre‑touching: files are pre‑created and pages are proactively touched via a pretoucher, so writes hit resident pages instead of triggering page faults.
> * Sequential, append‑only I/O: linear writes avoid random access, letting the OS keep pages hot and leverage readahead efficiently.
> * Off‑heap/direct memory: minimizes GC pauses and heap contention, keeping latency stable.
> * Bounded, fixed‑size blocks and rolling cycles: predictable allocation patterns reduce surprise faults and fragmentation.
> * Warm‑up on startup: touches mappings and populates TLB/page cache before latency‑sensitive work.
> * Optional mlock/pinning (where allowed): keeps critical pages resident to avoid paging.
> * Controlled durability: fsync can be tuned (or batched) to match real‑time latency budgets.
> * Pretouch (or pre-touching) means proactively accessing mmaped pages before latency-sensitive I/O so they are resident in memory and TLB/cache, avoiding on-demand page faults.
> * In Chronicle Queue, a pretoucher thread walks ahead in the append path and touches upcoming pages/blocks (often by writing small dummy bytes or reading headers). This:
> * Faults pages in early, populating the page cache and TLB.
> * Ensures sequential, append-only writes hit hot pages.
> * Reduces first-touch latency spikes during real-time operation.
* 18: [Linux性能分析工具汇总](https://mp.weixin.qq.com/s/W-BDRffMY3k3yj527HAGMw)
> * vmstat
> * iostat
> * dstat
> * iotop
> * pidstat
> * top
> * htop
> * mpstat
> * netstat
> * ps
> * strace
> * uptime
> * lsof
> * perf
* 17: [What Is a TLAB or Thread-Local Allocation Buffer in Java?](https://www.baeldung.com/java-jvm-tlab)
> * The JVM addresses this concern using Thread-Local Allocation Buffers, or TLABs. These are areas of heap memory that are reserved for a given thread and are used only by that thread to allocate memory.
> * launch the JVM with the -Xlog:gc+tlab=trace flag to see this information
* 16: [Java 25](https://mp.weixin.qq.com/s/lDWuhnBw0o1lDef0EHGElg)
> 1. vectorization
> 2. scoped values
> 3. structured concurrency
> * [Structured Concurrency in Java](https://www.baeldung.com/java-structured-concurrency)
* 15: [Guest Post: How I Scanned all of GitHub’s “Oops Commits” for Leaked Secrets](https://trufflesecurity.com/blog/guest-post-how-i-scanned-all-of-github-s-oops-commits-for-leaked-secrets)
> * GitHub Archive logs every public commit, even the ones developers try to delete. Force pushes often cover up mistakes like leaked credentials by rewriting Git history. GitHub keeps these dangling commits, from what we can tell, forever. In the archive, they show up as “zero-commit” PushEvents.
* 14: [为啥C++程序会在main函数之前崩溃?](https://mp.weixin.qq.com/s/y5qU166QGdCJMizjXtQqYw)
> * "静态初始化顺序问题"(Static Initialization Order Fiasco,简称SIOF)
> * 解决方案:Meyers Singleton
> * C++11保证局部静态变量初始化是线程安全的
* 13: [改进FAST协议解码性能](https://mp.weixin.qq.com/s?__biz=MzkxNDMyNzQxMw==\&mid=2247484333\&idx=1\&sn=c3ecfcd1d329efc3939ffe87b526db50\&scene=21\&poc_token=HEnTfmmjiCebEFDI7kE0q7O3cfqKpblG6GVQEtqa)
> * Stop Bit Encoded
> * chronicle bytes -> Typically, when we talk about a byte, a byte can represent one of 256 different characters. Yet, rather than being able to represent one of 256 characters, because we used Base64LongConverter we are saying that the 8-bit byte can only represent one of 64 characters. By limiting the number of characters that can be represented in a byte, we are able to compress more characters into a long.
> * ASCII
> * UTF-8 vs UTF-16
> * VByte 是一种“面向字节”的方案。在每个字节中,保留最高有效位作为控制位:当该字节是编码整数中的最后一个时,该位设置为 0,否则设置为 1。
> * 将一组控制位集中到前面后,减少了VByte对每个byte判断第一位控制位时引发的分支预测失败率。
> * vint-G8IU快在利用SIMD指令。vint-GB也能被SIMD,但它对于Group控制位后的数据位长度是不固定的(4\~16位)。因此在数据预取时会因长度不固定而导致cpu不时的停顿。而vint-G8IU每块数据都是固定的9位byte,在数据预取时,更加的可预测。
> * VByte -> vint-GB -> vint-G8IU -> Stream VByte
* 12: [Building a full-text search engine in 150 lines of Python code](https://bart.degoe.de/building-a-full-text-search-engine-150-lines-of-code/)
> [Bart de Goede](https://bart.degoe.de/) A full-text search engine consists of three main components:
>
> 1. analyze
> 1. tokenize
> 2. lower case normalization
> 3. punctuation removal
> 4. stop word removal
> 5. stem
> 2. inverted index
> 3. search
> 1. query parsing
> 2. precision search
> 3. relevancy search - [Understanding TF-IDF (Term Frequency-Inverse Document Frequency)](https://www.geeksforgeeks.org/machine-learning/understanding-tf-idf-term-frequency-inverse-document-frequency/)
> 1. Term frequency
> 2. Inverse Document Frequency
* 11: [Lessons Learned Shipping 500 Units of my First Hardware Product](https://www.simonberens.com/p/lessons-learned-shipping-500-units)
> From software engineer to hardware engineer.
* 10: [How to Scale a System from 0 to 10 million+ Users](https://blog.algomaster.io/p/scaling-a-system-from-0-to-10-million-users)
> A re-warm up.
* 9: [What is the purpose of std::launder?](https://stackoverflow.com/questions/39382501/what-is-the-purpose-of-stdlaunder)
> * [Programming Languages — C++](https://timsong-cpp.github.io/cppwp/)
> * Money laundering is used to prevent people from tracing where you got your money from. Memory laundering is used to prevent the compiler from tracing where you got your object from, thus forcing it to avoid any optimizations that may no longer apply.
* 8: [Placement `new` C++.](https://medium.com/@ajay.patel305/placement-new-c-b7f1e2e2077a)
> The placement new operator in C++ allows you to construct an object in a pre-allocated memory buffer.
* 7: [std::jthread: A safer and more capable way of concurrency in C++20](https://medium.com/bosphorusiss/std-jthread-a-safer-and-more-capable-way-of-concurrency-in-c-20-07121cec3a84)
> The destructor of a std::thread object with an associated thread calls std::terminate if join() has not been called.
* 6: [upper\_bound和lower\_bound](https://www.cnblogs.com/devgc/p/14599203.html)
> * [upper\_bound](https://en.cppreference.com/w/cpp/algorithm/upper_bound.html): Returns the first iterator iter in \[first, last) where bool(value < \*iter) is true, or last if no such iter exists.
> * [lower\_bound](https://en.cppreference.com/w/cpp/algorithm/lower_bound.html): Returns the first iterator iter in \[first, last) where bool(\*iter < value) is false, or last if no such iter exists.
* 5: [Debugging C++ with GDB](https://skewed.de/lab/manual/gdb/)
> * Compiling in debug mode will then include debug symbols (-g), disable optimisation (-00), and enable assert() by omitting -DNDEBUG.
> * [Debugging with LLDB](https://kevinushey.github.io/blog/2015/04/13/debugging-with-lldb/)
> * [codesign gdb in MacOS](https://gist.github.com/gravitylow/fb595186ce6068537a6e9da6d8b5b96d)
* 4: [超越 lock-free 的是 wait-free](https://mp.weixin.qq.com/s/kDKkNVWqjPaSzmvOc4U-7Q)
> * 在读操作占主导时,Wait-Free 表现极佳。因为读线程的“协助”行为分散了写线程的竞争压力,而且读操作本身不需要像 CAS 循环那样反复争抢缓存行。
> * 但在写操作占主导时,Lock-Free 反而更快。为什么?因为 Wait-Free 的那些位运算、状态判断、原子交换握手,都是实打实的 CPU 指令开销。而 Lock-Free 在竞争不激烈的时候,就是一个简单的原子加减,极其轻量。
> * [Introduction to Wait-free Algorithms in C++ Programming - Daniel Anderson - CppCon 2024](https://www.youtube.com/watch?v=kPh8pod0-gk)
> * [如何在不加锁的情况下解决多线程问题?](https://mp.weixin.qq.com/s/jo2nmv6ULijTuhk3wHHdPQ)
* 3: vcpkg and CMake
* [How CMake, vcpkg, and JSON Work Together: Explained for C++ Developers](https://www.youtube.com/watch?v=10kqdZR4rmU\&t=30s)
* CLion
* [Vcpkg integration](https://www.jetbrains.com/help/clion/package-management.html)
* [CMake profiles](https://www.jetbrains.com/help/clion/cmake-profile.html)
* [Quick CMake tutorial](https://www.jetbrains.com/help/clion/quick-cmake-tutorial.html)
* [CMake presets](https://www.jetbrains.com/help/clion/cmake-presets.html)
* [A TL;DR about CMake Presets](https://martin-fieber.de/blog/cmake-presets/)
* 2: [Create Your Own Compiler](https://citw.dev/tutorial/create-your-own-compiler)
> TODO
* 1: [Transforming Uniform Random Variables to Normal](https://codefying.com/2015/02/25/transforming-uniform-random-variables-to-normal/)
> * Central Limit Theorem (CLT) Method (12 Uniforms): [Generate Gaussian samples by central limit theorem](https://medium.com/@seismatica/how-to-generate-gaussian-samples-1cbf46b49751)
> * Inverse Transform Sampling: [How to generate Gaussian samples](https://medium.com/mti-technology/how-to-generate-gaussian-samples-347c391b7959)
> * Box-Muller Transform: [Box-Muller](https://medium.com/@seismatica/how-to-generate-gaussian-samples-3951f2203ab0)
> * Beasley-Springer-Moro Algorithm
> * [Marsaglia polar method](https://khanhnguyendata.medium.com/how-to-generate-gaussian-samples-c645c09d142e)
>
> [Random Numbers Generator](https://codefying.com/2015/02/11/random-numbers-generator/)
>
> * linear congruential generator
>
> [Transforming Uniform Random Variables to Normal](https://codefying.com/2015/02/25/transforming-uniform-random-variables-to-normal/)
>
> * Box-Muller Transform
> * Beasley-Springer-Moro Algorithm
> * Inverse Transform Method
### [2025](/gems/2025-gems.md)
### [2024](/gems/2024-gems.md)
### [blogs](/gems/blogs.md)
## Contacts
 >
> * [How Does std::enable\_if work?](https://stackoverflow.com/questions/25284499/how-does-stdenable-if-work)
> * `template
>
> * [How Does std::enable\_if work?](https://stackoverflow.com/questions/25284499/how-does-stdenable-if-work)
> * `template